
The World as Model
A research series on sensing, representations, and the financialization of the physical world

Every durable market begins with a better model of the world.
High-frequency trading firms didn’t win because they had a deeper theory of markets. They won because they found representations in which prediction became economically useful. As prediction becomes abundant, the scarce asset is no longer the model. It’s the representation, sensing architecture, and market infrastructure that make prediction actionable.
At millisecond timescales, markets exhibit statistical structure that largely disappears at lower resolution. HFT firms built systems that captured, organized, and acted on those signals before anyone else could. Their edge wasn’t that they discovered some esoteric “truth” of markets. It was that they discovered a representation where enough predictive signal existed to trade profitably. The edge was structural and nearly impossible to copy.
The same transition is beginning in the physical world.
Factories, mines, power grids, satellites, and data centers are becoming information systems for the first time. The companies that figure out how to render physical reality at its native resolution won’t just build better tooling. They’ll determine how trillions of dollars of physical assets are financed, insured, and traded.
This series outlines how we might build the representation layer for the physical world and the new markets that become possible once it exists.
Representing Reality
Language is a compression format optimized for human to human communication. When humans began to code computers, we forced reality through that same filter. The current generation of AI systems inherited this constraint directly: the digital world has been built on language so language is what the training data contains. LLMs are extraordinarily capable within that bottleneck. They are also, by construction, blind to many things outside of it.
As AI systems become capable of generating and curating their own training data and as new modalities like vision, robotics, and physical sensing enter the training pipeline, the language bottleneck begins to loosen. The question becomes: what is the optimal compression format for different domains of reality?
The best representation is not necessarily the richest one. It's the simplest representation that preserves the information required to accurately reconstruct or predict the system's behavior.
The models that would let the industrial economy and its constituent parts reason natively don’t exist yet. That is beginning to change. A new generation of companies is building digitally native representations of industrial processes, from metal cutting and injection molding to isotope production and copper mining.
Whoever discovers the correct geometry for the physical world will compress reality more efficiently, make better predictions at lower cost, and ultimately determine how physical assets are financed and priced.
Said simply - the companies that can develop, build, and deploy this whole “reality stack” for physical infrastructure will define the financialization of this reality. Our work at Crucible is finding, funding, and scaling these companies.
The Curse of Dimensionality
Every domain of reality has a native resolution at which signal becomes recoverable. The economic opportunity lives in finding it.
This is one of the oldest and most practically consequential problems in data science and it’s having a renaissance right now given what it means for AI inference cost, vector database economics, and large scale data collection design.
Richard Bellman’s Curse of Dimensionality describes this well - data sparsity grows exponentially as you add dimensions. In English, a fixed sample size of data points becomes less representative as you add dimensions.
You see this in this simple graphic where we demonstrate data sampling across increasing dimensions. Every dimension you add makes your data sample less representative of the space, because each dimension increases your data set by an exponent.
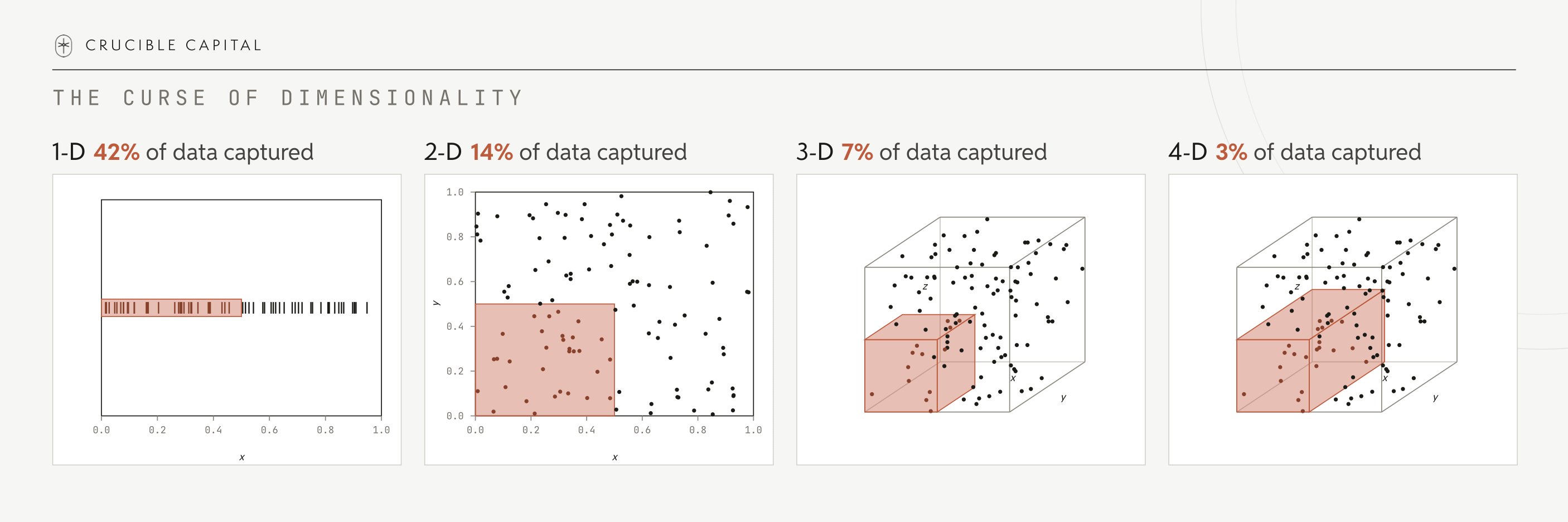
Every representation is ultimately a decision about compression. The conventional response to the Curse is to reduce dimensions. Project down to something tractable and work there. That works in the digital world, where you have a handful of modalities to compress. The physical world has hundreds, many of which we are only beginning to instrument.
The Curse of Dimensionality assumes that you are sampling uniformly and blindly, with no prior knowledge of where the signal lives. Luckily, for most physical systems that assumption is false because we have something called science - matter and energy have predictable behavior, rooted in two centuries of scientific discovery.
Physics gives the structure. Thermodynamics tells us which variables are coupled. Fluid dynamics constrains how pressure propagates. Material behavior constrains how systems deform, fatigue, and ultimately fail. The signal is not uniformly distributed across a high-dimensional space—it is concentrated on a much lower-dimensional manifold shaped by physical law. The result is that the representations generated from sparse sensing are sometimes not reliable.
Dr. Fei Fei Li expresses the translation challenge elegantly:
Three-dimensional data with explicit geometry, material properties, and physical annotations is orders of magnitude scarcer than the internet video that renderers train on. The sim-to-real gap, which is the difference between how things behave in simulation and how they behave in reality, persists. Generative simulators introduce a new risk on top of that: AI-generated geometry can look correct while containing self-intersections or wrong scale that produce nonsensical physics. Multi-physics simulation at scale, where rigid bodies, deformable objects, fluids, and cloth all interact, remains orders of magnitude more expensive than single-domain simulation.
This translation problem, going from physical reality to machine legible representation, is where the opportunity begins.
Data Collection at Native Resolution
Today’s physical data landscape occupies two extremes: sparse or dense, with very little in between.
On one end: dense acquisition.
Collect everything. This end of the domain almost never exists in the physical world today because sensing hardware has high costs that scale linearly with node count. Perhaps the one area where we have seen dense acquisition is autonomous driving, particularly with Tesla’s approach, because the cost of failure is loss of life. With almost every other physical activity, there is no dense data acquisition.
On the other end: sparse acquisition.
This is most of the physical world today. The unit economics of data collection make it more cost efficient to collect specific events only, using structured triggers and methodologies. This is efficient but brittle, limiting resolution and potentially presenting a sampled manifold of reality that does not reflect what is actually happening in a physical system.
There are large parts of the world that have not yet been digitized, where there is little to no dataset available. Optimal data collection will require both hardware and software to find the resolution that matches the use case and is dynamically adjusted, fine-tuning granularity as needed based on the defined rules of that system. The economics of the LLM era are highlighting the need for new methodologies that match sensing hardware, data topologies, and models to the underlying economics of intelligence.
Extreme resource constraints are fantastic drivers of technological progress. We are moving from an age of energy and compute abundance to one of structural scarcity that will persist for a long time. There has never been a better time to invest in the next generation of companies that will push these frontiers forward, changing cost curves through novel methods to reduce energy and compute needs.
The Future of Industrials Looks Like a High Frequency Trading Firm
At Crucible, we view the world through the lens of capital markets. The reindustrialization movement leans heavy on mechanical and industrial engineering but pays less attention to financial engineering, a dynamic that must and is rapidly changing. Capital markets are the mechanism by which scarce physical assets are most efficiently allocated. The last five centuries of economic growth have been built on this reality. Markets are the backbone of a robust industrial economy.
For further proof points: see our recent writing on the next energy unicorn being a trading desk, commodity and currency hedging, the plastics industry needs data, freight, and financing
Markets are one of the few domains where signal has historically been non-linguistic. Price is not a word. Order flow is not a sentence. The information content of a market lives in time-stamped sequences of events, each carrying position, velocity, and context; a structure that has nothing to do with language and everything to do with geometry.
High frequency trading firms understood this and built accordingly. HFTs didn’t simply collect more data. They built the highest-fidelity representation of reality. Every successful representation is ultimately an answer to the curse of dimensionality: which variables matter enough to preserve, and which can be discarded. They won by building representations that live at the native resolution of the signal, microstructure patterns that are invisible at any lower sampling rate, and then owning the requisite physical infrastructure to ensure they could monetize this intelligence before anyone else.
The edge was durable because it was structural and proprietary. Owning the right representation is not an advantage one could easily copy. It required building the proprietary data collection infrastructure, the analytical layer to organize the data, translating that signal into strategy, and then executing it in real time before anyone else, recursively improving in a tight feedback loop.
That structural moat is now being contested for the first time — not by rival HFT shops, but by frontier AI labs with the compute to compress years of strategy development into months. The window for durable representation advantages in markets may be narrowing.
In industrials, it is just opening.
Physical infrastructure — machines, pipelines, power systems, buildings, vehicles — generates continuous signals across hundreds of modalities. Most of those signals go uncaptured today, at least not by the operators and their lenders. The ones that are captured are rarely at the resolution where data becomes predictive rather than merely descriptive. A temperature sensor polled every fifteen minutes tells you a machine ran hot. A continuous vibration signature at millisecond resolution tells you a bearing is failing three weeks before it does.
The difference is not the sensor — it’s the sampling architecture.
The data topologies that would support physical intelligence at scale barely exist yet.
We are in phase zero.
The opportunity is to build what HFTs built for markets, but for the physical world: native-resolution data collection, representations that match the geometry of physical signals rather than forcing them through linguistic pipelines, and ultimately market infrastructure through which better physical intelligence becomes executable financial positions.
What This Series Covers
This series, published over the coming month, will build from the ground up.
We start with sensing. Sensing is how machines sample reality. Physics is not the problem in sensing, it’s manufacturing and unit economics. We will outline how novel methods for sensing hardware and software can enable data collection at its native resolution.
We then move to data topologies and the intelligence stack — how representations compress reality. Raw signal becomes structured information, what the edge-to-cloud architecture actually looks like in industrial deployments, and why most organizations are stuck here.
We then examine models, which reason over representations. Specifically, which architectures are native to physical and sensor data rather than adapted from language pipelines. Physics-informed representations, geometry and topology-based learning, world models that predict the next state of a physical system rather than the next token, time series models that track state change as the primary signal. Each is a bet on a different geometry for a different domain of reality.
We close with markets — the financialization layer where better physical intelligence becomes a tradeable position. For example, depreciation tracked by sensor readings and translated into dynamically priced residual value insurance (our portfolio company Aravolta is doing this for GPUs already). Industrial asset securitization becomes possible when the surveillance layer is live telemetry rather than periodic inspection reports. That market already exists at the high end. Jet engines, commercial aircraft, and now GPU clusters are actively monitored because the asset values and maintenance obligations are large enough to justify the cost, and the lenders who finance these assets have strict debt covenants. Lower the cost of native-resolution monitoring and you shift the efficient frontier of what is financializable to an increasingly larger set of industrial assets. This is the prize.
The thesis running through all of it is that capital flows follow information density. The information density of the physical world is exploding. The companies that build the right representations will own the edge — not just in analytics, but in the markets that price, trade, and transfer risk for the largest and most consequential investment cycle in human history.
The end of the beginning. Part 1 on Sensing will be linked here when it’s published. Subscribe to get our writing in real time.
Thanks to Mike Chieco for being a thought partner and to Sarah Hoback for providing constructive feedback. Each piece in this series is informed by the founders building these frontiers. My DMs are always open.
Additional References
Dr Fei Fei Li: A Functional Taxonomy of World Models